
在Linux内核中对VFS与具体的文件系统关系划分如下:
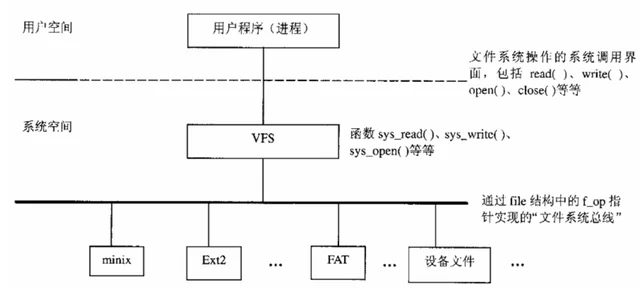
虚拟文件系统(VFS)的作用就是把不同的具体文件系统进行抽象,屏蔽了底层不同具体文件系统的实现细节,形成一个抽象层,然后对外(应用层)提供一个统一通用的接口。
当进程操作文件时,首先通过C标准库(libc)函数进入VFS层调用统一的系统调用函数。

对于进程,每操作一个文件都会有一个对应的 struct file 结构,该结构记录的是具体已打开文件的有关信息。
当多个进程同时打开同一个文件,那么,每个进程都有自己的file结构,也即是都有自己的打开文件的上下文。
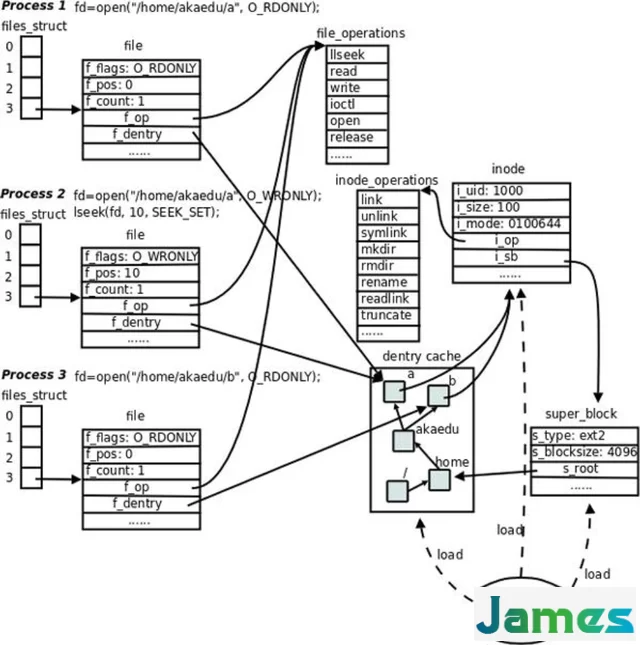
file 结构中的 f_op 指向该文件所属的具体文件系统的 struct file_operations 结构。所以,该 struct file_operations 结构是虚拟文件系统 VFS 与具体文件系统之间连接的桥梁。
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
};
每个具体文件系统都会实现一个structfile_operations结构,
比如 ext2 文件系统的实现如下:
struct file_operations ext2_file_operations = {
llseek: ext2_file_lseek,
read: generic_file_read,
write: generic_file_write,
ioctl: ext2_ioctl,
mmap: generic_file_mmap,
open: ext2_open_file,
release: ext2_release_file,
fsync: ext2_sync_file,
};
当操作文件时,系统调用会调用具体文件系统的实现方法,从而从虚拟文件系统层进入具体文件系统层。
从虚拟文件系统层进入ext2文件系统层过程如下:
read
-> sys_read
-> file->f_op->read => generic_file_read
write
-> sys_write
-> file->f_op->write => generic_file_write
inode用户存储文件的各个属性信息,比如文件的所有者信息(owner、group)、权限信息(r、w、x)、时间信息、标志信息、数据块的位置等等。
struct inode {
...
//记录inode下所有dentry
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;
kdev_t i_dev;
umode_t i_mode;
nlink_t i_nlink;
uid_t i_uid;
gid_t i_gid;
kdev_t i_rdev;
loff_t i_size; //以字节为单位的文件大小
time_t i_atime;
time_t i_mtime;
time_t i_ctime;
unsigned long i_blksize; //以位为单位的块大小
unsigned long i_blocks; //文件的块数
struct inode_operations *i_op;
struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
struct address_space *i_mapping; //指向下面的i_data
struct address_space i_data; //该字段与ext2_inode_info中的数组i_data[]不一样
struct dquot *i_dquot[MAXQUOTAS];
...
union {
struct minix_inode_info minix_i;
struct ext2_inode_info ext2_i;
struct hpfs_inode_info hpfs_i;
...
} u;
};
inode 信息在磁盘中保存的是具体的文件系统 inode 信息,比如 ext2 文件系统在磁盘中保存的是 struct ext2_inode 结构。
struct ext2_inode {
__u16 i_mode; /* 文件类型和访问权限 File mode */
__u16 i_uid; /* 文件拥有者uid低16位 Low 16 bits of Owner Uid */
__u32 i_size; /* 以字节计的文件大小 Size in bytes */
__u32 i_atime; /* 文件的最后一次访问时间 Access time */
__u32 i_ctime; /* 文件创建时间 Creation time */
__u32 i_mtime; /* 修改时间 Modification time */
__u32 i_dtime; /* 删除时间Deletion Time */
__u16 i_gid; /* 块组id的低16位 Low 16 bits of Group Id */
__u16 i_links_count; /*链接计数 Links count */
__u32 i_blocks; /*文件所占块数 每块以512字节计 Blocks count */
__u32 i_flags; /* 文件打开方式File flags */
union {
...
} osd1; /* OS依赖描述结构osdl OS dependent 1 */
__u32 i_block[EXT2_N_BLOCKS];/* 指向数据块的指针数组 Pointers to blocks */
__u32 i_generation; /* NFS文件版本 File version (for NFS) */
__u32 i_file_acl; /*文件访问控制链表,已经不再使用 File ACL */
__u32 i_dir_acl; /* 目录访问控制链表 已不再使用 Directory ACL */
__u32 i_faddr; /* 碎片地址 Fragment address */
union {
...
} osd2; /* OS dependent 2 */
};
dentry在内核中起到了连接不同的文件对象inode的作用,从而起到了维护文件系统目录树的作用。在dentry中包含了文件名、文件的inode号等信息。
struct dentry {
atomic_t d_count;
unsigned int d_flags;
struct inode * d_inode; /* Where the name belongs to - NULL is negative */
struct dentry * d_parent; /* parent directory */
struct list_head d_vfsmnt;
...
struct qstr d_name;
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block * d_sb; /* The root of the dentry tree */
unsigned long d_reftime; /* last time referenced */
void * d_fsdata; /* fs-specific data */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
};
dentry 只是一个单纯的内存结构,由文件系统在提供文件访问的过程中在内存中建立。在磁盘中保留的是具体文件系统的 dentry 结构,比如 ext2 文件系统中在磁盘中保存的是 struct ext2_dir_entry_2结构。
struct ext2_dir_entry_2 {
__u32 inode; /* Inode number */
__u16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT2_NAME_LEN]; /* File name */
};
dentry、inode 属于 VFS 层的数据结构,适配不同的具体文件系统,而ext2_dir_entry_2、ext2_inode 结构是专属于具体文件系统ext2而设计的结构。当然别的具体文件系统也有自己的dentry、inode结构。ext2_dir_entry_2、ext2_inode结构保存于磁盘中,VFS层的 dentry、inode除了包含很多动态的信息之外,还是对后者的一种抽象和扩充。
ext2文件系统将磁盘划分为大小相等的记录块来管理。
在设备上是以记录块为单位进行分配。从读/写效率上考量,记录块当然是越大越好,但是记录块打了往往会造成空间的浪费。因此,权衡之下,ext2选择以1K字节为默认记录块大小。当然为了读写效率,也可以把采用2K或4K字节。
为了方便磁盘的管理和从效率上的考虑,又把若干个记录块组组成一个大的记录块组,称为块组。块组是ext2文件系统的管理单元。
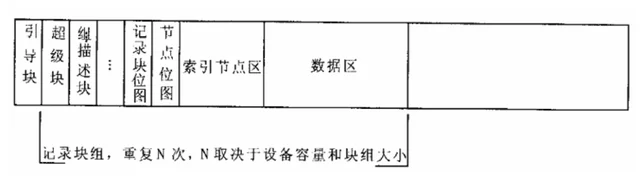
引导块是作为引导操作系统用的,在文件系统作为根文件系统时使用。在系统加电启动是,其内容有BIOS自动装载并执行。它包含一个启动装载程序,用于从计算机安装的操作系统中选择一个启动,还负责继续启动过程。因此Ext2文件系统把这个区域预留出来,不作为文件系统管理的磁盘区域。
超级块: 记录此文件系统的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;由于super block很重要 ,在每个 block group都会存一份进行备份,一般来说,第一个数据块中是原始超级块,其它数据块组中都是超级块的备份。
组描述块就是对本块组的描述,其中包括该块组中数据块位图的位置、inode位图的位置、inode表位置、本块组空闲块的数量等信息。在ext2文件系统中,组描述块结构为 struct ext2_group_desc,存在于块组中的第二个记录块。
每个块组都有一个组描述块,读取各个块组的组描述块放到一块就形成了一个组描述符表。
记录块位图则是本块组的位图,占用的块数取决于块组的大小。用于索引节点的记录块数量取决于文件系统的参数,而索引节点的位图则不会超出一个记录块。
索引节点区保存的是一个一个 inode 信息,对于 ext2 文件系统,里面保存的是一条条 ext2_inode 结构,当恢复内存数据的时候,内存中的 inode 以及inode中的 ext2_inode_info 信息很多都是从磁盘中ext2_inode结构中恢复的。比如 inode.ext2_inode_inf.i_data[] 都是从 ext2_inode.i_block[] 中恢复的。
数据区里面的记录块有可能保存的是 dentry,也有可能是文件里面的数据。当保存的时 dentry 时,不同的文件系统保存的具体 dentry 结构也不相同,比如 ext2 文件系统,磁盘中的保存的为 ext2_dir_entry_2 结构。
在操作系统中物理内存被划分为以4k为单位的页,而磁盘中是以记录块(1K)为大小的进行划分。
在内存中页的高速缓存是由内存中的物理页面组成,对应的是磁盘上的物理块。在早期的 linux 内核中,同时存在 PageCache 和 BufferCache。PageCache 用于缓存对文件操作的内容,按照文件的逻辑页进行缓存。BufferCache 用于缓存直接对块设备操作内容,按照文件的物理块进行缓存。在内核版本2.4以前二者属于半独立状态,这要造成了整体性能的下降和缺乏灵活性。因此在2.4以后,二者进行了融合,BufferCache 的内容直接存在于 PageCache 中。
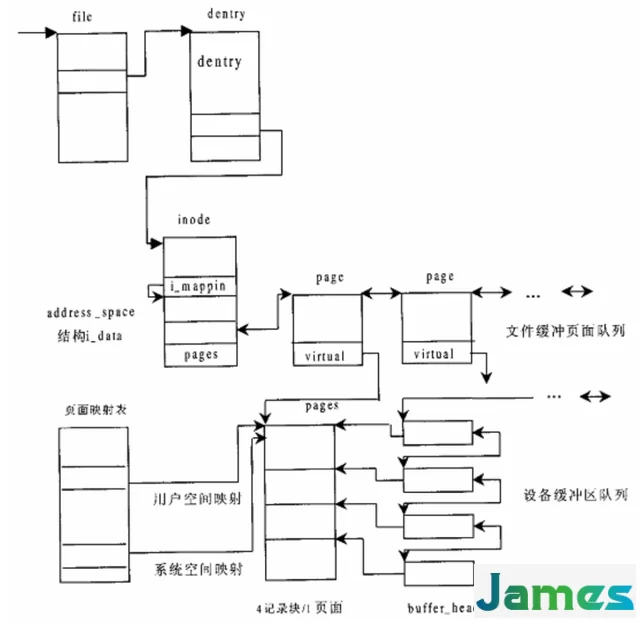
一个物理页面占4k,而一个磁盘记录块占1k,因此一个物理页面使用4个buffer_head。每个页面对应的buffer_head组成一个链表,同时每个buffer_head的b_data指向物理页面中对应的内存区。
那么物理内存里的数据是怎么和磁盘的记录块进行关联的呢?
在ext2文件系统的 ext2_inode_info结构中,有一个大小为15的整形数组i_data[15],其通过直接映射以及间接映射完成了内存中的数据到磁盘中记录块的映射。
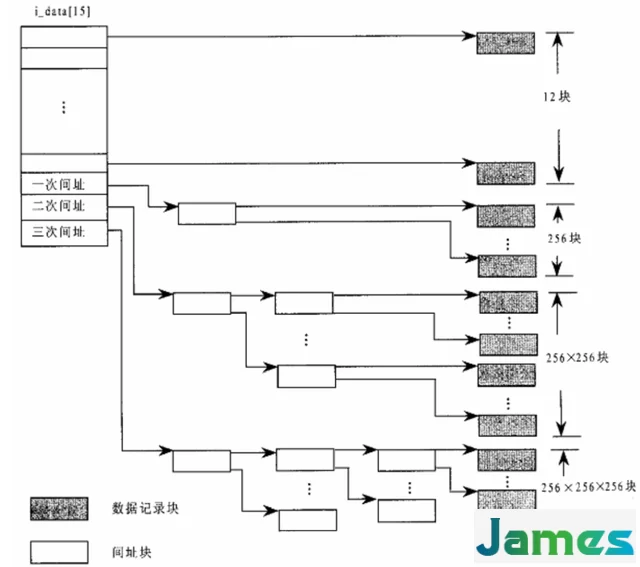
开头12项完成的是直接映射,里面保存的是文件前12k的的数据,比如文件的前1k数据对应磁盘的数据块号会被写入到i_data[0]中等。
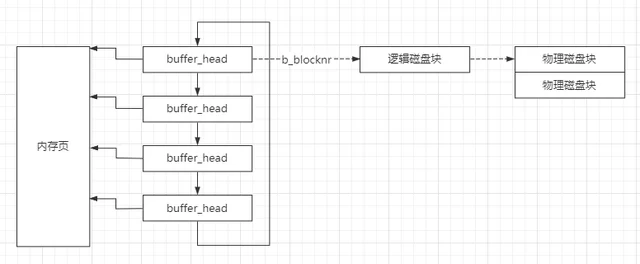
由于记录块是以1k为单位,因此数组中的每个元素保存的是设备上的记录块号。通过记录块号以及inode中保存的设备号就可以定位到该记录块号在哪个设备上的哪个扇区。同时这个记录块号也会保存到 buffer_head的b_blocknr中。
数组后面几项完成的是间接映射、二级一映射和三级映射。
关于Linux IO栈大致如下,也可以参看官方给的IO栈http://www.ilinuxkernel.com/files/Linux.IO.stack_v1.0.pdf
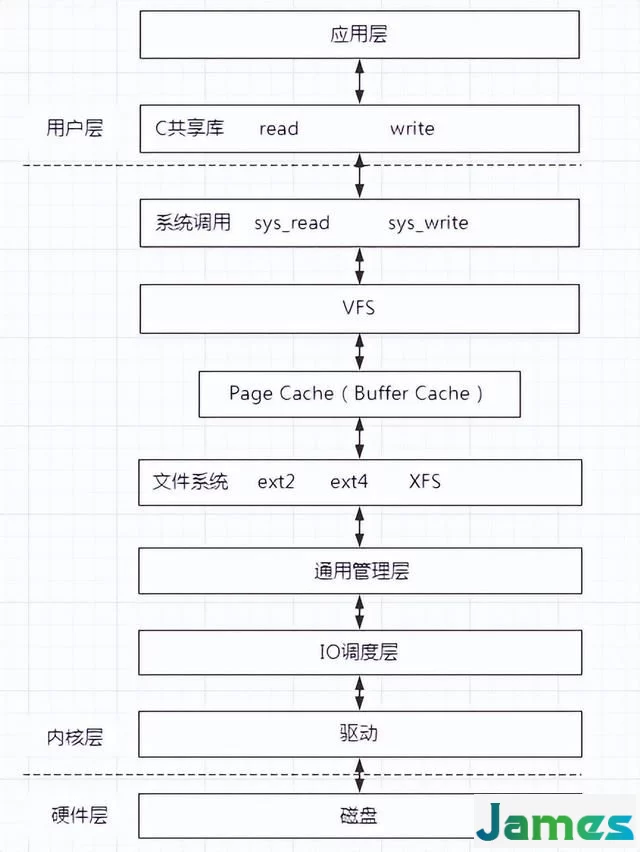
应用程序通过调用lib库中的接口进入系统调用,有系统调用进入内核层。
在内核层首先进入虚拟文件系统VFS,虚拟文件系统主要是对底层不同文件系统进行抽象,对上提供统一接口,对下屏蔽具体文件系统细节。在 VFS 中有四个核心结构 super block、dentry、inode、file。
在VFS下面就是Page Cache,也就是页高速缓存。它是使用内存对文件数据进行缓存,提高访问速度。若访问的block恰好在内存页中,这直接返回,不在进行磁盘操作。若不在内存,这申请一个内存页,然后对磁盘进行IO,然后把数据放到内存页中。
如果想节省内存,不想使用Page Cache,想绕过内存直接进行磁盘IO,则设置 DIRECT_IO 即可。
文件系统层就是进入了具体的文件系统,不同的文件系统都有自己的操作方式。
不同的文件系统处理后,向下进入通用层。通用层会把请求的数据块block转化为一个请求对象,然后把请求对象加入到设备的请求队列中。
IO调度层的作用就是为了磁盘IO性能最大化,利用电梯算法等对记录块连续的IO请求进行合并。使得磁盘读写数据时尽可能按照顺序读写,提高效率。
然后通过驱动对磁盘进行IO。
下面通过对文件写操作分析下其调用过程
sys_write-> file->f_op->write => generic_file_write 进入具体文件系统-> __grab_cache_page 获取或建立一个缓冲页面-> mapping->a_ops->prepare_write => ext2_prepare_write-> copy_from_user 用户数据写入到缓冲页面中-> mapping->a_ops->commit_write => generic_commit_write 把缓冲页面交给内核线程kflushd,写回设备-> __block_commit_write 提交写入的数据-> __mark_dirty 把buffer_head加入到合适的LRU队列中-> balance_dirty 查看脏状态的记录块是否积累到一定数量,若是唤醒bdflush进程就从LRU队列中取出记录块进行冲刷-> wakeup_bdflush 唤醒bdflush进程进行冲刷或本进程进行冲刷-> wake_up_process 唤醒bdflush进程进行冲刷,bdflush调用bdflush不停的进行冲刷--> bdflush->flush_dirty_buffers--> ll_rw_block(WRITE, 1, &bh)-> flush_dirty_buffers 若着急,本进程直接进行先冲刷-> ll_rw_block(WRITE, 1, &bh)-> submit_bh 提交到IO调度层进行I/O操作-> generic_make_request 将IO请求发送的设备IO队列-> __make_request 合并IO请求-> elevator->elevator_merge_fn =>elevator_linus_merge 使用电梯调度算法进行IO合并-> q->request_fn => do_ide_request 启动IO-> ide_do_request-> start_request-> DRIVER(drive)->do_request => do_r


